
In recent years, countless new modern data platforms have been implemented. Yet I see that the impact & results achieved with these new state-of-the-art platforms are often disappointing. While the techies are often insanely enthusiastic, this enthusiasm is not always widely shared. The hoped-for effect that the rest of the organization – including management and board – were so eagerly awaiting does not materialize. Recognizable?
The mistake often made is thinking that a new & modern data platform is “the solution. This is not true, in fact it is just a (good) start.
In this blog, I give 5 concrete next steps that you need to address as part of the implementation of your new data platform. At least if you want the data in your platform to actually be used.
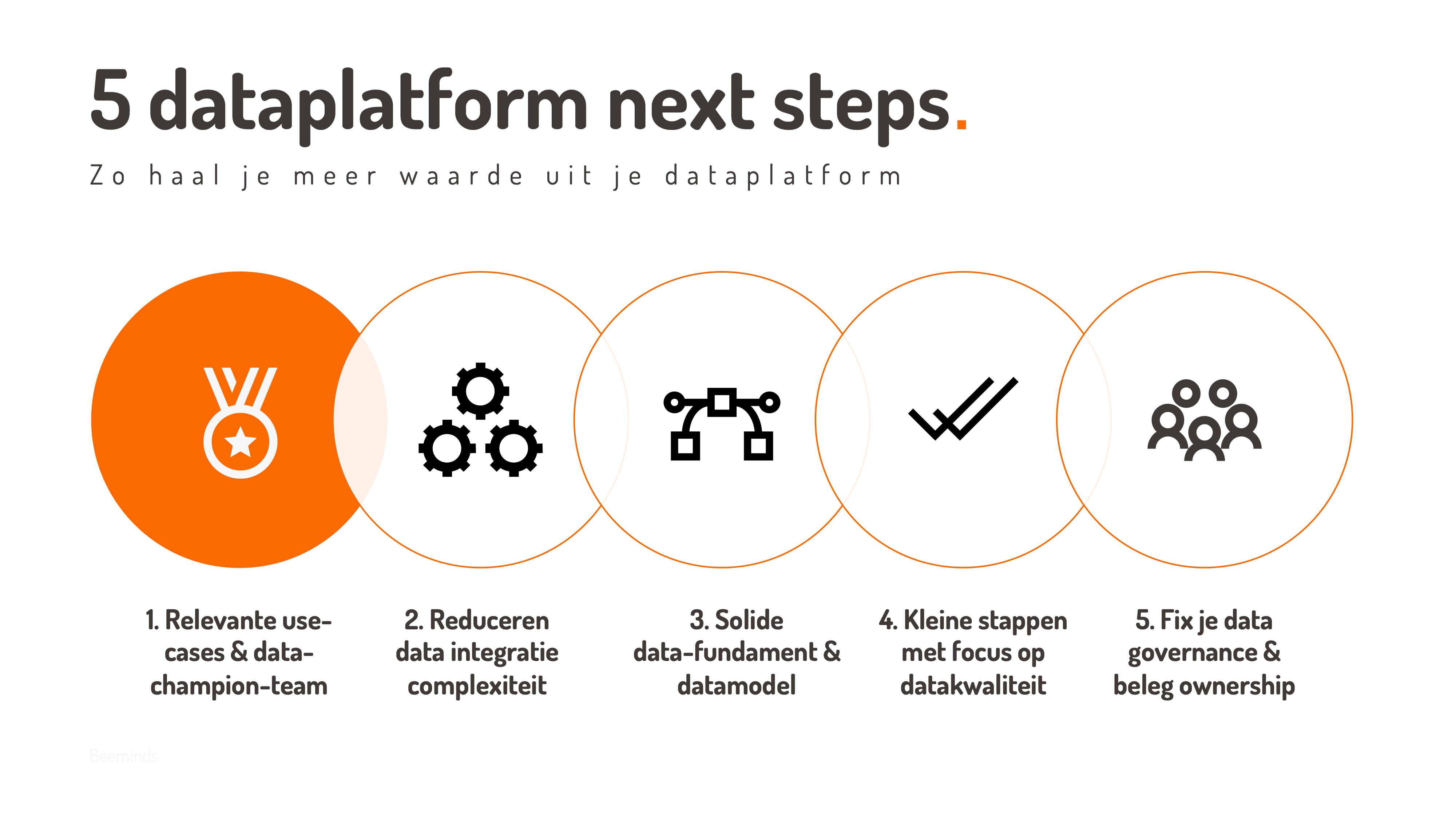
Treat your new data platform like an electric car

Before I get into the first post-data platform must-do, I want to reflect on all these new data platforms. After all, a good data platform is important. It drives all your data initiatives. In fact, it’s more than an engine: it’s your new car that everyone in your organization will be moving around in over the next few years! An electric car to be precise, if you compare it to the traditional data platforms that are often still based on non-cloud-native technologies & platforms.
Traditional data warehouses are often cumbersome & expensive and cannot be migrated 1:1 to the cloud. Logical then to implement a modern data platform in 1x, right? Yes, definitely. But like driving an electric car, it does require some adjustment in some parts. In theory, a new data platform is (much) cheaper, more efficient and faster. But depending on how you use the platform, that could be quite disappointing.
How to best deploy such a modern platform is another topic that I will create a separate blog about in the future. However, I do want to share one tip for all organizations on the eve of implementing a new data platform:
Don’t spend more than two months fully implementing a new data platform!
Following this tip only also has one implication. And that is that you are not going to design & implement the data platform yourself! And that is exactly my point: for 95% of the organizations it has no significant added value to design & implement a (new) data platform yourself. So don’t do that, is my appeal!
Consider this: are you really going to become more distinctive as an organization because you came up with the solution architecture of your data platform yourself? The answer is probably “no. What you do stand out more by is putting your time & energy into developing data products using a platform that you purchase as a service. The improvements you can realize with this in efficiency, new revenue and customer experience are the things you can really distinguish yourself with! Even if you are not yet ready and want to be the first to make the step to the cloud with your data warehouse, a platform that you can purchase as a service is a wise choice.
Anyway, I see that many organizations are (too) quick to resort to self-building, which in many cases is unnecessary. So my advice is:
First, define your “Buy vs. Build” strategy. Consider whether you need to develop your own data platform or whether you can purchase a suitable one. The latter is the logical choice for >95% of organizations.
Once you have made this decision, you can start looking for a suitable data platform that you can purchase as a service today. In doing so, it is important to formulate answers & principles on the following aspects:
- Define what type of data streams the platform must handle
Data comes in many shapes & sizes. Just how you think about charging speed, range & trunk space with an electric car, you do the same with a data platform.
- Define specific requirements around security & data privacy
A data platform often contains a lot of sensitive data, so it is important to be clear whether you are dealing with specific rules here that you need or want to take into account.
This list is simple, and that is deliberately done. Of course, there are many more aspects to consider when selecting a platform, but it is not very different from selecting any other platform or software package.
If you do this selection well, then in no time you will have a new & equipped modern data platform, with which you can actually get started and start adding value to your organization!
Must-do 1: Form a data team & focus on relevant use cases
Time for the first must-do! And this is #1 for good reason, because this is directly where things often go wrong. Ensure relevance! It sounds very logical, but since many organizations still approach data projects from a technical perspective, not continuously focusing on business relevance is a trap that many organizations unfortunately still fall into.
So put together a multidisciplinary (virtual) team with people who are excited about the opportunities of data and can collectively make it concrete. This need not be a full-time role – especially in the beginning – but of course that depends on your data maturity level & ambition. Have the team work on a list (backlog) of relevant use cases and make them concrete with examples.
The following three aspects are important in forming this team:
- Multidisciplinary:
select & involve people from the operational field and supplement this with people who have an affinity for data. IT can certainly participate, but make sure IT is not dominant. Forming the team & starting from enthusiasm is definitely a good approach and ensures support within your organization. You can always adjust (where necessary) and adapt/expand the team at a later stage. - Sponsor
: Get a sponsor from management who actively participates in discussions & can make decisions. Data is often an (important) part of a strategy these days. This team ensures that your strategy can come to execution. A call to the boards of organizations to make time for this. - Execute
: make sure you free up at least one person enough to work things out & make them concrete. Preferably do this with visual examples so that it is communicable. For example, you can take this up with a strategic supplier or with your own data analysts and/or data scientists.
Inspiration as a catalyst
One of the main tasks of this team is to inspire your organization so that new ideas are released and these ideas are aligned with your organizational strategy. A good way to do this is through interactive workshops organizing.
A common objection is that the data initiatives from the organization do not align with the organization’s strategy. In that case, I have one tip: ask individuals to present your strategy on 1 sheet. Chances are your strategy has not been communicated clearly (enough).
New ideas, by the way, do not always have to be innovative. We often forget that innovation is a means & not the end and that innovation can mean something different for each organization. For one sector, a new digital assistant powered by ChatGPT that handles your customer questions is innovative, while another sector would be greatly helped by a “simple” dashboard that allows them to see the margin per customer.
Must-do 2: reducer data integration complexity
A lot of time & energy is lost in something that is important, but doesn’t need to take that much time & energy. This is about unlocking & reading the data into your data platform, also known as “data integration.
These integrations – often referred to as ETL or ELT– are housed in data pipelines and are essential in making data available to your organization. If a data pipeline isn’t working properly, chances are the data shown in your dashboards won’t be accurate or your predictive AI/Machine Learning model won’t work. Data pipelines today you can build in a no-code way
implement, but many data engineers prefer code-driven pipelines, making you dependent on specialist knowledge in case of an incident. Of course, sometimes there are good reasons to ‘program’ a data pipeline, but with good data architecture & tooling, that doesn’t have to be ‘the norm’ these days. So set a ‘guideline’ for your data & IT teams when to choose which solution direction.
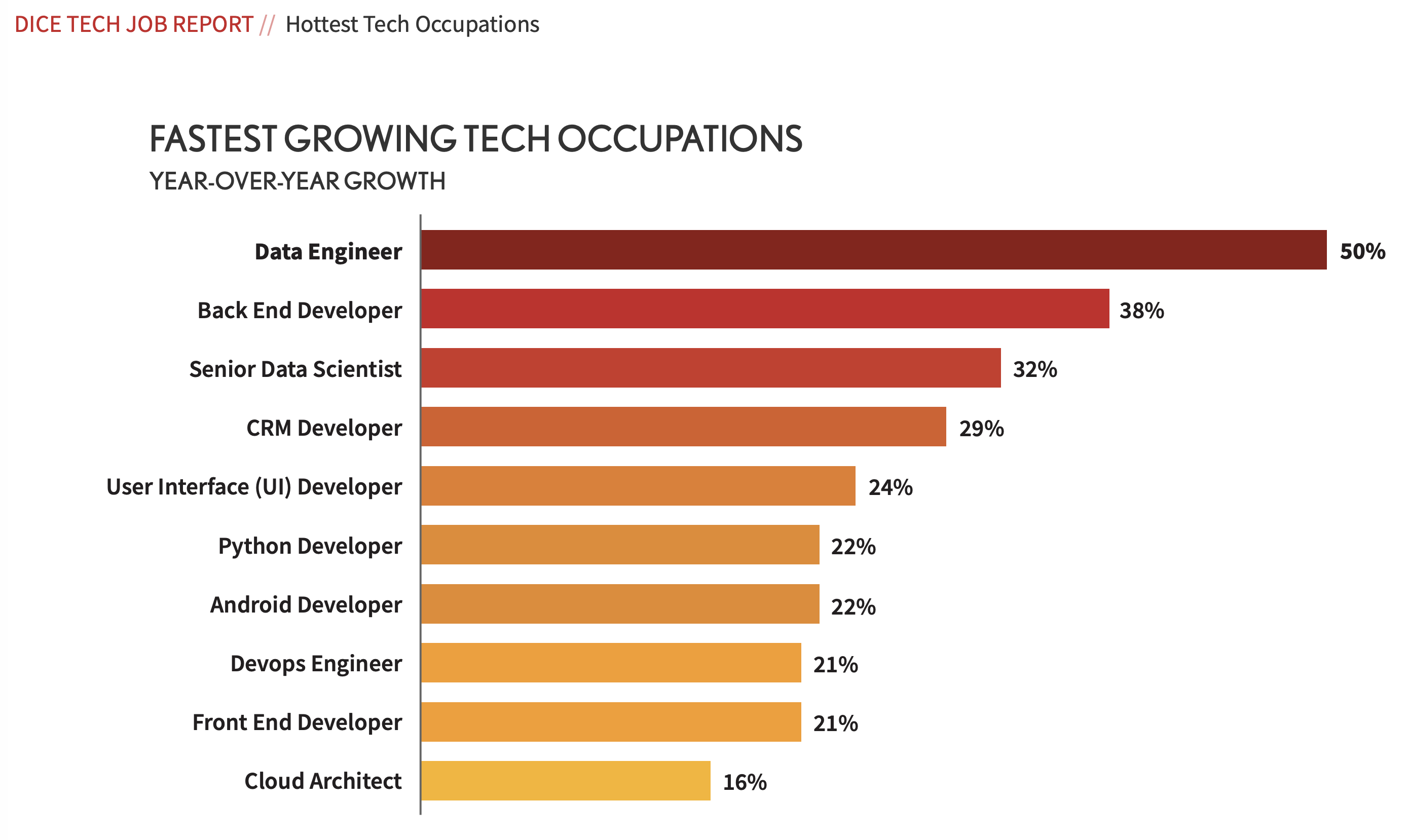 Data Engineer: a popular profession
Data Engineer: a popular profession
If you depend on data in your primary process, there is even something to be said for wanting to keep an eye on it 24×7. Therefore, it makes sense that “data engineer” is one of the most popular professions of our time:
Data Integration as-a-Service
So, if possible & logical, choose an integration solution that you can purchase “As-a-Service. Nowadays there are Many connectors or integrations can be found that you can purchase as a service (data integration-as-a-service) for a fixed amount per month. One of the big advantages of this is that you outsource the management & maintenance of the connection to a party that has a team that can monitor this 24×7 and be called to account as soon as something is not working (properly).
After all, all that matters is that the data enters your data platform in a safe & reliable manner. The time you save by not having to set up and maintain this yourself can be spent on any special applications for which no as-a-service integration is available or ensure that you focus more on increasing data quality. The latter is guaranteed to bring you more benefits in the successful deployment of data within your organization.
Must-do 3: Create a data foundation & start with a supported data model
The linking of systems discussed above is often seen as the starting point of the data journey. Somehow logical, since you need data to get started with data.
Yet this is strange, because even in the most agile & innovative environments, the “first think, then do” principle still applies. So my call to organizations – to keep working with data manageable & affordable – is also:
Start with your data end-state, and fill your data model in a phased & structured manner. First design, then build!

Part of that end-state is not only your data model, but also what data products are relevant to your organization and what they should look like. I last came across this (old) quote in relation to the AI revolution now underway, but it also applies here.
Starting with the goal and design the ‘end-state’
Make an overview of what data you really need to deliver a particular use case and land it in a well thought out data model. This way the data is clearly documented & findable and you can create data quality rules to ensure the data is of guaranteed high quality.
This approach has 3 main advantages:
- No “over-engineering”:
avoid unnecessary complexity & maintenance because you don’t unlock applications or data that you don’t need and therefore don’t need to maintain. Data pipelines can become quite complex as time goes on because they contain many moving parts, so the less unused functionality they contain; the better. You avoid “over-engineering” in this way - Speed & simplicity:
you make the job easier for your data engineers because you provide a well-thought-out landing place (data model) where the data must “fit in. This also increases quality. - More effective & efficient:
you determine the need of a particular data product (use case) before spending often scarce technical resources on building a new integration. So it helps you in creating relevant data products that – when your data governance process does its job properly – are in line with your data strategy. My colleague Gerbrand Tjaden recently wrote a blog on how to build an effective data warehouse that actually aligns with an organization’s needs. In this blog, this point is also emphasized and with this you actually kill two birds with one stone. Low-hanging fruit!
In the last 5 years, data modeling has become a lost art , as in recent years there was a lot of reliance on data lakes where you write away data in raw format without the need to know the data model. However, this has resulted in many data swamps instead of data lakes, so data modeling, among other things, is gaining popularity again.
The fact that the importance of having a good data foundation is coming back again is completely justified as far as we are concerned. A well-thought-out data model has many advantages, 3 of which I will mention here:
- Documented & searchable:
if you know what data you want to include in your model, you can also document these fields. After all, you only need to keep track of it in 1 place. As an added benefit, you can also make this data searchable for end users with a data catalog and display this documentation in your data analysis tool, making it clear, for example, exactly how your YoY margin development is calculated. - Validated & recognizable:
a good data model is recognizable & understandable for the (end) users. You can validate this and thus increase support. It thus becomes easier to start realizing data products based on a well-thought-out data model. - Higher adoption & transparency:
validated data that is searchable will ensure higher adoption of data within your organization as it is easier to get started. In addition, it also helps with ownership of data. The latter is especially important in decentralized data governance frameworks such as data mesh where you work with data contracts. Here, data ownership is central. It also helps that when users have questions about certain data, that they know who to turn to.
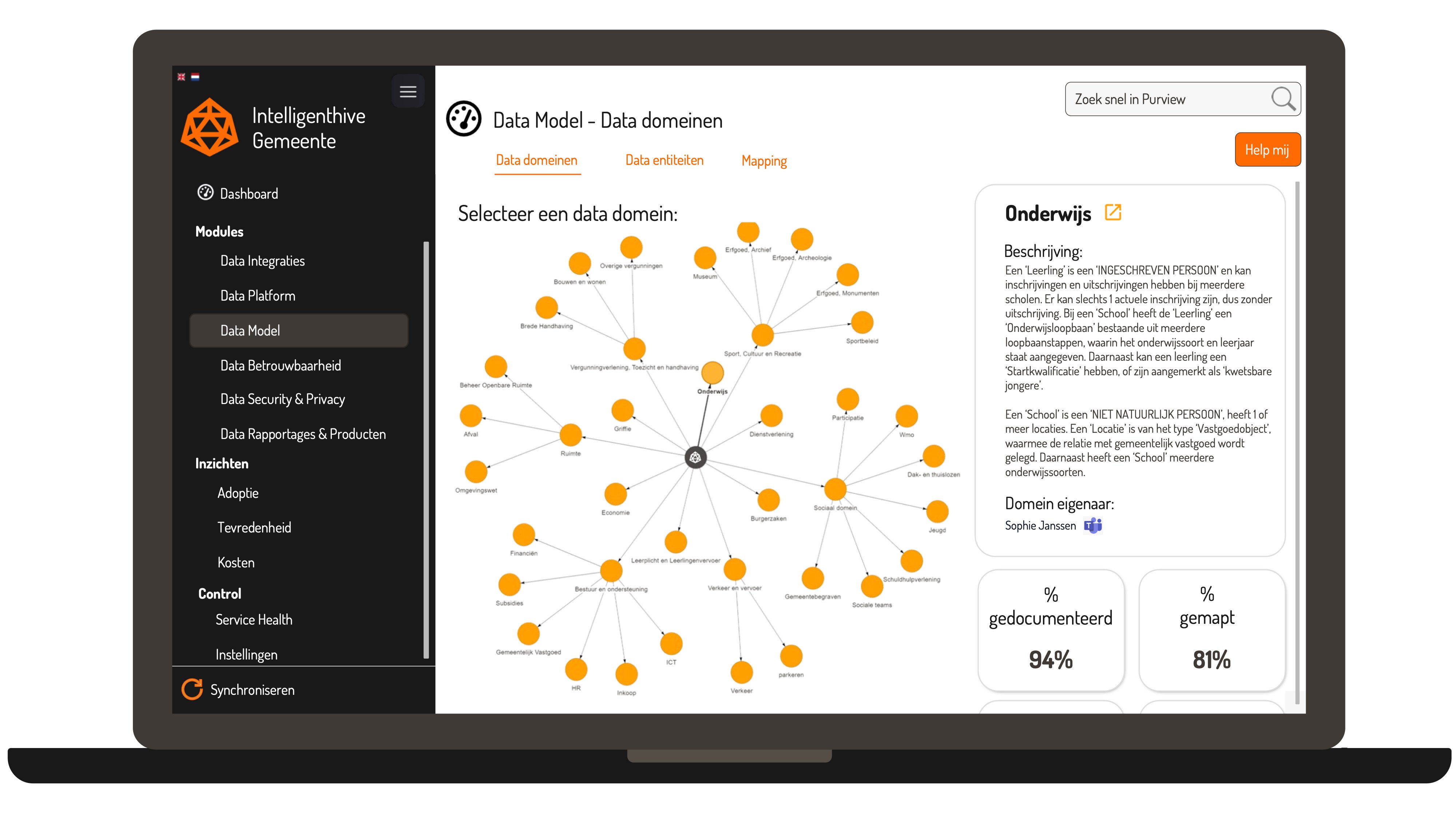
A data model or Enterprise Data Model (EDM) can be quite complex to visualize. At Beeminds, we use a visual representation to make the data domains & data entities and the relationships between them understandable to the organization in a simple & interactive way:
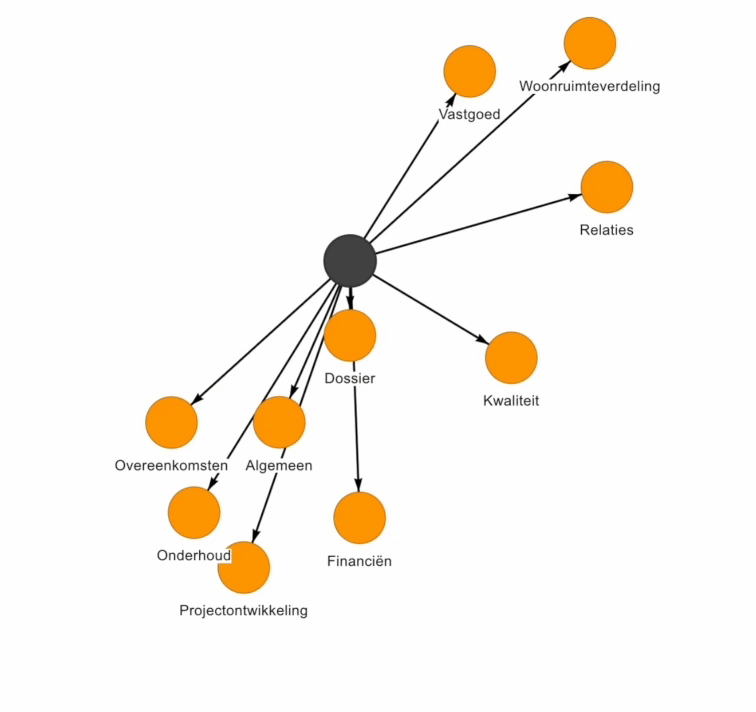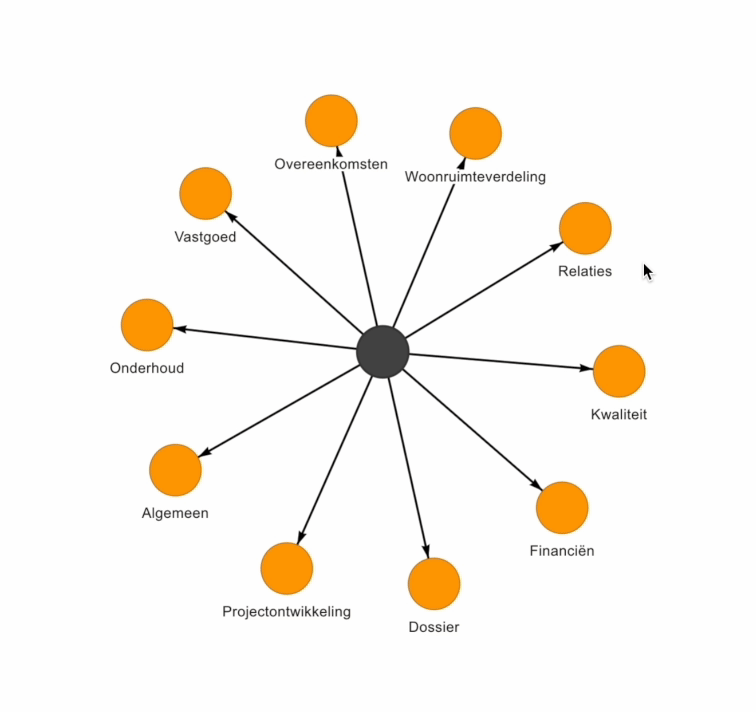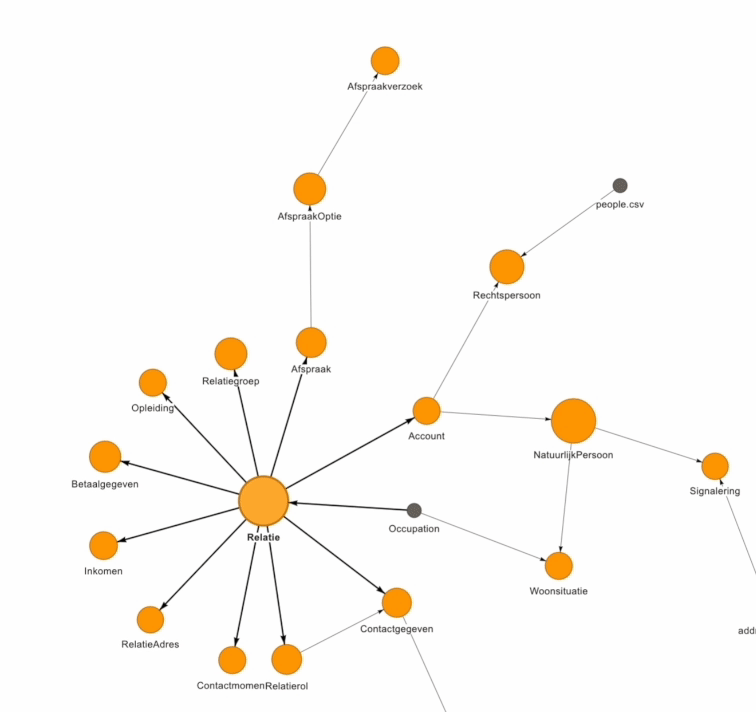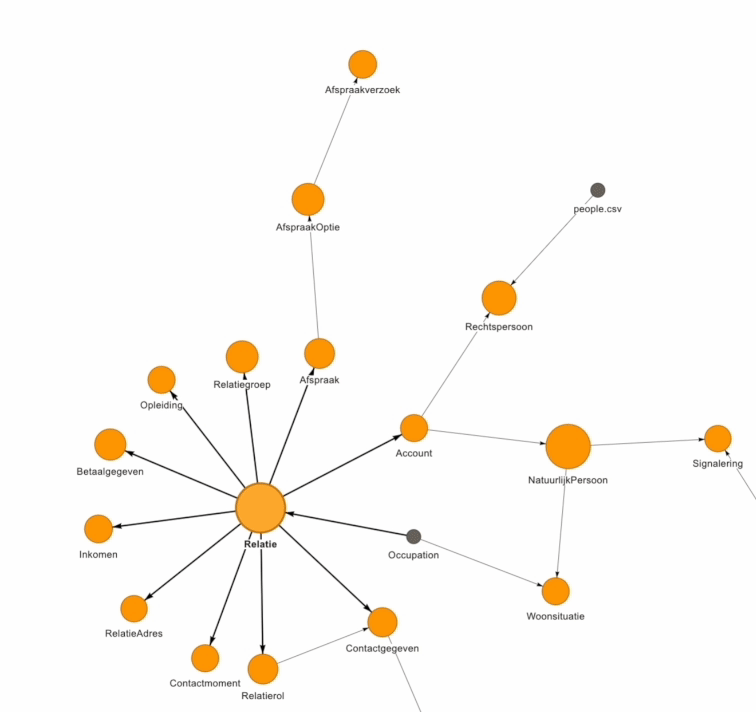
Must-do 4: Take small steps with a focus on data quality
The most common expression when deploying data products within organizations is the comment, “I don’t know if I can trust the data…”
Often this lack of trust is fueled by complex dashboards that raise more questions than answers and by conclusions & insights that are simply not explainable. A critical moment for building or losing this trust is the launch & presentation of a KPI or insight based on the data. Based on the recognizability & explainability of the data shown, a conclusion is immediately drawn by those with an interest in it. If the data shown is not recognized or understood, it will irrevocably have a negative impact on trust in the solution. Follow the following 3 steps:
- Start small:
of course we would like 1 dashboard where all the desired insights are given, but unfortunately this is not possible. In fact, this only increases the risk that your dashboard will not be understood & used. So start small and with maximum relevance to mitigate this risk. - Validate:
make sure you validate insights with the most important stakeholders and ask them the following 2 questions: “do you recognize the insights shown?” and “are the insights shown correct?”. After all, it may well be that your insights are correct with conclusions not previously known. If so, then question 1 influences the answer to question 2. There is a difference between “being right” and “being proven right. So validate your data products so that any ambiguities are removed before launch. - Explain:
make sure you build & explain your insights logically. Visibly explain to users how certain calculations or graphs are constructed and provide clear descriptions of the data. Have you excluded certain data? If so, state this as well.
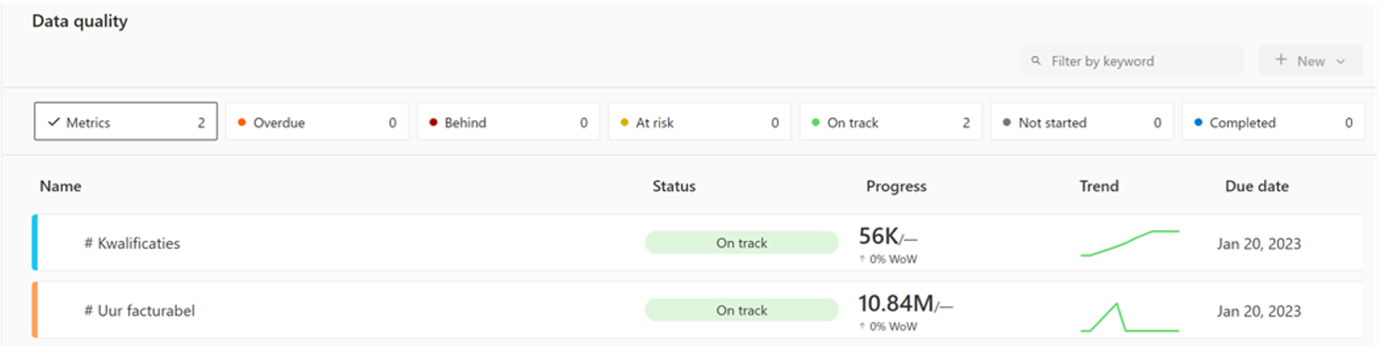
Data quality
Still, you’re not there with the above steps. Because once you have launched your data product, it is very important that you keep an eye on whether the data shown is still correct. Data quality is an important process that you must therefore ensure not only during, but also after realization. After all, the data used is a ‘moving target’ that is constantly changing. To get a grip on this, the following are essential:
- Make arrangements with application owners
Make sure you are transparent to the owners of the applications your data comes from and make it clear what data & how you use it. By communicating your dependencies, you create awareness and reduce the risk of data changes taking you by surprise.
- Invest data ownership
Make sure you have a clear owner designated to guard your data. Read more about this in the latest must-do number 5.
- Set up (automatic) data quality rules
By setting up a set of data quality rules that are automatically checked, you are already preventing many errors. These rules have one purpose, which is to send a signal to the right person who can do something with it. Data quality rules can be created relatively easily based on a current dataset, especially when you use standard frameworks. At Beeminds, we use the Great Expectations framework, which integrates seamlessly with virtually any data platform.In addition, it is very useful to monitor data quality based on the past (trends). We all know that past results are of course no guarantee for the future, but if you read 1,200 changed records every day and suddenly there are only a few left structurally, that is at least a reason to send a signal. A dashboard to perform such checks & signals comes standard with every use case and delivers significant added value in every data project.
Must-not-do
What is at least as important is what not to do. And that, as far as I’m concerned, is to “fix” poor data quality in the (business) logic your data platform. By doing so, you create logic that is complex to maintain, since you are not structurally solving the problem. So mopping up with the faucet. Always talk to the owner of an application to see if you can solve the problem at the source.
Must do 5: Invest ownership & fix your data governance
As indicated earlier, many data platform implementations focus on technology. Data governance & data ownership can be supported with technology, but fundamentally it is about agreements, processes & your organization.
Data ownership has come up several times in previous must-do’s, and it’s important to think about this carefully. By data ownership, I don’t mean investing all data-related matters with one person who knows the most about it. At first, this seems like the most obvious solution, but it quickly leads to two major drawbacks:
- Bottleneck & speed
When data adoption increases (and it will, because you’ve followed up on the first 4 points ;-)), you’ll soon see that putting all data-related challenges in the hands of 1 person is going to create a bottleneck that will slow down the speed of delivering data products and solving problems.
- No challenge & attrition
Data ownership often involves operational work. Investing all operational data work in one talented person will lead to less challenging work. When you stuff talented people with operational work and don’t challenge them, you run the risk of these people falling into a bore-out and even eventually leaving your organization.
Make data ownership transparent and communicate it to the organization. A data catalog such as Microsoft Purview makes this very easy:

In short: keep your data organization agile and spread your data ownership within your organization from the beginning. In addition, it also helps in creating wider support & increasing adoption.
To data mesh or not to data mesh?
Today, many organizations are considering ‘Data Mesh ‘ as an approach to properly organize data governance within your organization. Also, the recently announced Microsoft Fabric & OneLake offers native support for Data Mesh. Which way of organizing best suits you I will write a blog about it soon.
The goal? More relevant data & less complexity
I hope I’ve given you a push in the right direction with these 5 concrete must-do’s & tips if you’re considering implementing a new data platform or if you’ve already done so.
My goal with this is simple: more focus on relevance, but with less complexity. Will you guys let me know if you got anything out of this blog?
Data-as-a-Service reduces complexity
At Beeminds, we like to make things simple and believe that the road to data-driven work for organizations can be shorter. Data as water from the tap, that’s our promise!
And that is exactly what we deliver with our Intelligenthive solution. The above topics are of course included and can be purchased as a service with a service level that suits your organization.
Wondering how we solve these challenges and provide your organization with a data foundation? Then schedule a demo today and be convinced!
share post
































