
In November 2023, Microsoft announced that Microsoft Fabric will be ready for production use. A good idea, we at Beeminds think, because Microsoft Fabric is Microsoft’s data platform on which all future data developments will take place. Still, there are two other platforms that can be purchased in the Microsoft cloud and that currently have more users than Fabric. We would like to list the differences and similarities for you.
Microsoft Fabric: what is it?
Since Microsoft Fabric is “the new kid on the block,” I begin with a brief introduction to this new platform. Microsoft Fabric offers a suite of data services that are well integrated with each other. These services cover various aspects of the data journey: from data discovery to processing and presentation.
Should you be interested in exactly what these services entail, I recommend you watch the video about Microsoft Fabric by my colleague Richard Verburg and myself, in which we cover these services one by one.
OneLake & Purview are important
When I talk about Microsoft Fabric, I actually also always talk about ‘OneLake’ and ‘Microsoft Purview’. Since the total cost & service of a Microsoft Fabric implementation is also partly determined by these services, I think it would be good to briefly explain them as well:
- OneLake: one central data layer that allows you to efficiently store or access your data regardless of where it resides.
- Microsoft Purview: the central tool you can use to support your data governance processes (spoiler: and much more in the future :-)).
So you see that OneLake and Microsoft Purview are in fact an essential part of Microsoft Fabric and in practice these services integrate seamlessly with each other. OneLake isn’t called the “OneDrive for your data” for nothing.
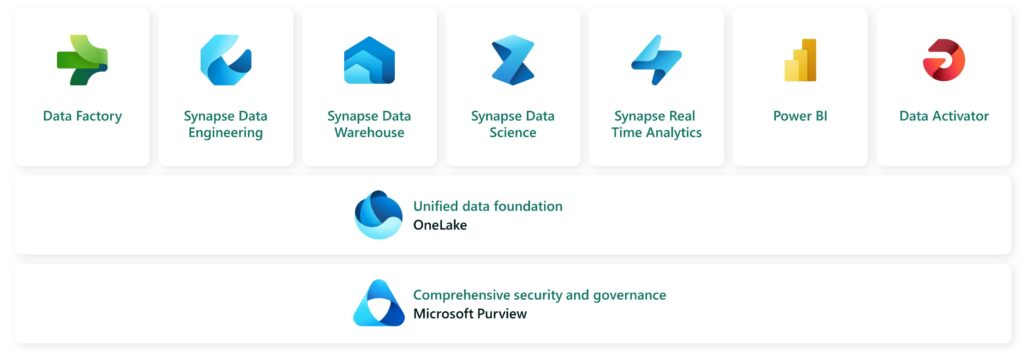
The role of OneLake
In the overview below, you can clearly see how OneLake takes a central role in creating one central data lake with all your relevant business data. Microsoft’s vision is that no matter where your organization, partners or data teams store their data, you can unlock it through OneLake.
This does not require making copies of your data, keeping in mind that even OneLake is not exempt from natural laws. In some cases – due to performance requirements – you will still need to make a copy of your data. With a price of about 0.22 cents per gigabyte per month, most organizations won’t notice that much, but less duplication also means less complexity & maintenance.
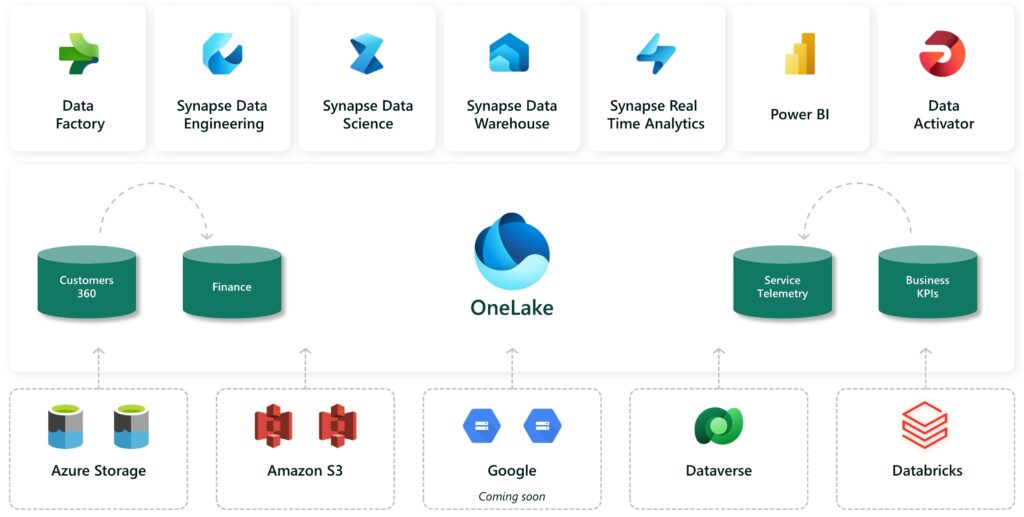
Positioning: Databricks & Snowflake
So Microsoft Fabric is a data platform, just like Databricks and Snowflake. These platforms compete with each other, but Microsoft’s route of attack – or rather route of attack – is one in which we see Satya Nadella’s “new Microsoft” in its purest form: namely, a platform organization that maintains strong partnerships.
Despite the fact that the platforms are absolutely rivals to each other, Microsoft chooses a route where they primarily state that it doesn’t matter where your data resides or what platform you use to manage that data. Microsoft Fabric and OneLake ensure that you are in control of your data and that for some use cases you can use Microsoft Fabric with data in the Azure cloud and for some use cases you can house Databricks with data from AWS or even data in Snowflake which you then manage through Microsoft Purview.
The partnership between Microsoft and Databricks is strong and we foresee many integrations between Microsoft Fabric & Databricks. Both platforms are standardized on the ‘Parquet/Delta’ format for storing data. This is something that greatly enhances data interchangeability: the integration of Databricks with OneLake makes it easy to write data processed in Databricks away to OneLake, and vice versa, of course. In addition, both platforms use a medallion (data) architecture which allows both platforms to embrace the same mindset around managing your enterprise data.
The partnership between Microsoft & Snowflake is more about being able to use the Snowflake platform in the Microsoft Azure cloud and being able to manage the data stored in the Snowflake platform through Microsoft Purview. Snowflake is traditionally a closed data platform, which means that the mechanisms they use to process and store data are not open standards. Recently, however, Snowflake did announce that they have open-source “Iceberg tables, which are similar to the Delta/parquet support of Microsoft Fabric & Databricks. For now, however, Snowflake is not stepping away from its own developed standards and this is “just” an addition to the existing platform.
So Microsoft is taking a “keep your friends close, but your enemies closer” approach. An approach that in my opinion could turn out well. Many organizations have already invested in a new Databricks or Snowflake data platform in recent years and saying goodbye to it now is not an easy move because of investments already made.
Databricks: Microsoft’s favorite
Microsoft’s picture of the future is clear: it is fine to use multiple data platforms side by side. The side note here is that in most of Microsoft’s future pictures you see a dual role for Microsoft Fabric i.c.m. Databricks more often than Microsoft Fabric i.c.m. Snowflake. Given the relatively old & strong partnership and similarities in the (open) architectures, this is not very surprising.
Choose one? Or several?
Having multiple data platforms may be possible on paper, yet the reality is different when I speak with most CIOs, CDOs or architects of midsize organizations. Many of these organizations struggle with the complexity these platforms bring. In addition to the complexity, the overhead of having & maintaining multiple platforms simply costs additional money.
So my expectation is that while there will certainly be experiments with multiple platforms, ultimately an organization will make a conscious choice about which platform it will choose. Sometimes that choice – as with multi-cloud – will be consciously for multiple platforms, but I foresee that the majority of organizations will want to standardize on one data platform.
The differences & so what?
Although there are quite a few technical & functional differences between the platforms, again they are not very different from each other: all three focus on storing and processing data.
There are many blogs written that go into all the underlying details, but my position here is that for 95% of organizations it doesn’t matter that much. All three platforms are capable of handling large amounts of data securely. In addition, all three vendors are reputable names in the data & analytics world and the visions are powerful & distinctive.
The following explanation of the differences is highly simplified, but usually hits the mark when I talk to organizations about choice:
- Microsoft Fabric
is a no-maintenance SaaS service that is highly integrated with the Microsoft suite and has many advantages – both functionally and in terms of licensing costs – when you also use Power BI. It largely satisfies all real-time & analytics data needs and makes data interchangeability easier by using the open-source Delta format. Microsoft is investing in many low/no-code solutions to make data processing more accessible. Microsoft Fabric uses the open-source Spark engine, but can only be used in the Microsoft cloud. This makes it an ideal solution for organizations that have a “Microsoft, unless” policy. - Databricks
is the favorite data platform of many a data engineer, and that’s because they are usually just one step ahead of the rest in terms of embracing new features. It is a “code-first” platform, with many things handled via scripts, which makes automating your data platform easier. Databricks can be taken in multiple clouds and is known for reference cases where gigantic amounts of real-time & batch data are processed by their platform. Databricks also uses open-source formats, including Delta and the Spark engine. - Snowflake
is a powerful data platform with its own engine, devised by two co-founders of Oracle. Snowflake had a performance advantage over other platforms for a very long time because of its unique way of storing data. Namely, this data is written away in an optimized format, allowing it to be used quickly in reports, for example. This advantage has now been somewhat superseded by the rapid developments that the other platforms have gone through, but this enormous performance combined with a unique marketplace that Snowflake offers for exchanging data and linking with publicly available data sources still makes it an interesting solution for organizations that find Databricks just a step too technical. Snowflake can also be hosted in the AWS and Google clouds.
Which platform is best for your organization you will definitely need to spend some time researching, especially if you have special requirements. In a previous blog ‘A new data platform. And then? I explain which two questions you can ask yourself to find out if you have ‘special’ requirements.
Nevertheless, I advise you to read the above ‘summaries’ of the platforms and determine on this basis whether a platform is already dropped or strongly preferred. Doing so might save you a lot of time & energy.
Ecosystem & personnel also relevant
When choosing a data platform, you are not just choosing a technology, but an ecosystem of solutions and the personnel required for that. So if you want to use e.g. (managed) services around data integrations, data quality, data security or data governance, you would do well to include these in your exploration as well. It is also good to look at your current staff or suppliers, since the skills & experience you need often have to come from there.
Cost: apples & pears
Comparing costs between different data platforms is – unfortunately – not very easy. There are different billing models and many of them are based on the computing power required, which in turn is highly dependent on your requirements, data, the modules purchased and… the chosen platform. This makes it very difficult to make a good realistic comparison. Snowflake works with credits, Databricks with ‘Databricks units’ and Fabric works with capacity units.
The vendors themselves, of course, indicate that their own platform is up to 12x cheaper than the alternative. Unfortunately, we also see – partly thanks to the independent tests conducted by the community – that this is difficult to prove in practice because it depends on many aspects. In addition to platform costs, as an organization you also have to deal with personnel costs that are difficult to plot objectively on the different platforms.
In my experience, Microsoft Fabric is a “challenger” in terms of price and the entry level is relatively low (starting from +- 250 euros per month). Snowflake has the image of being expensive – especially when used incorrectly – but you get a lot of functionality in return. Databricks is an advanced platform and this is reflected in the (entry) costs which are, for example, at least 2x as high as Microsoft Fabric.
In a future blog, I will elaborate on what a data platform costs on average.
In short: don’t stare blindly at the cost calculations that are done for you, but pay particular attention to making sure that you are deploying your data platform properly, as the wrong data architecture can cost you a significant amount of money either way in this new cloud world. Cost management is more important than ever in this regard.

What about… Azure Synapse Analytics?
One data platform you hear less about now is Azure Synapse Analytics, the predecessor to Microsoft Fabric. It has been unofficially confirmed that this service will remain and be maintained for now, but it should be clear that all new developments are going to take place in Microsoft Fabric.
The good news is that all your data and virtually all your pipelines can be transferred to Microsoft Fabric relatively easily. Recently, Microsoft released some guidelines on how best to prepare your organization for an eventual migration which are shown in the diagram below:

Tip: get advice and assistance from your current data platform partner in migrating to Microsoft Fabric or contact Beeminds for a no-obligation quote.
The differences are widening
Another reason to not just look at the state of ‘today’ when choosing a data platform are developments such as, e.g., Microsoft Fabric Copilot. These new features powered by AI are going to have a big impact on how organizations & teams use data.
A data platform is just the beginning
Of course, having a data platform does not automatically solve everything for you. For example, many organizations want to become data-driven, but having a data platform is only one element that is often used for that purpose. I explain the next steps you need to take after that in this blog.
The steps that come after choosing a data platform become even more important in view of previously mentioned developments such as Generative AI & Copilot, for example. Topics such as data quality, data privacy and data governance deserve a structural implementation within organizations if developments such as Generative AI and Copilots are to come into their own. I also wrote about this earlier in my blog ‘Innovating with Data, AI & ChatGPT without data management? Don’t think so!
The final score: (g)a prediction
Which data platform is going to win is hard to predict. I don’t think one platform is going to win, just as in the public cloud race between AWS, Google and Microsoft, there isn’t really one winner either. And maybe that’s just as well.
Still, I think the “new kid on the block” – Microsoft Fabric – is a good contender to quickly become very popular. The functionalities are already impressive, the entry-level pricing is good, there is a win-win in terms of cost if you already use Power BI or want to start using it, and Microsoft of course has a huge off market with its Microsoft 365 platform where Microsoft Fabric is now ‘on’ by default.
Selecting a data platform is only the first step in your entire data journey, and in fact, in most cases, most objectives with data can be met with any of the three platforms mentioned above.
So make sure that you consider the steps after the data platform choice and that you do not dwell too long on choosing a platform. During this ‘standstill’ you can only make a limited impact with data and that is after all what it is all about for an organization that wants to become more data-driven.
share post
































