
In de laatste jaren zijn er ontelbaar veel nieuwe moderne dataplatformen geïmplementeerd. Toch zie ik dat de impact & resultaten die zijn behaald met deze nieuwe state-of-the-art platformen vaak tegenvallen. De techneuten zijn vaak wel waanzinnig enthousiast, maar dit enthousiasme wordt niet altijd breed gedragen. Het gehoopte effect waar de rest van de organisatie – inclusief management & directie – zo op zaten te wachten blijft uit. Herkenbaar?
De fout die vaak wordt gemaakt is dat we denken dat een nieuw & modern dataplatform ‘dé oplossing’ is. Dit klopt niet, het is namelijk slechts een (goed) begin.
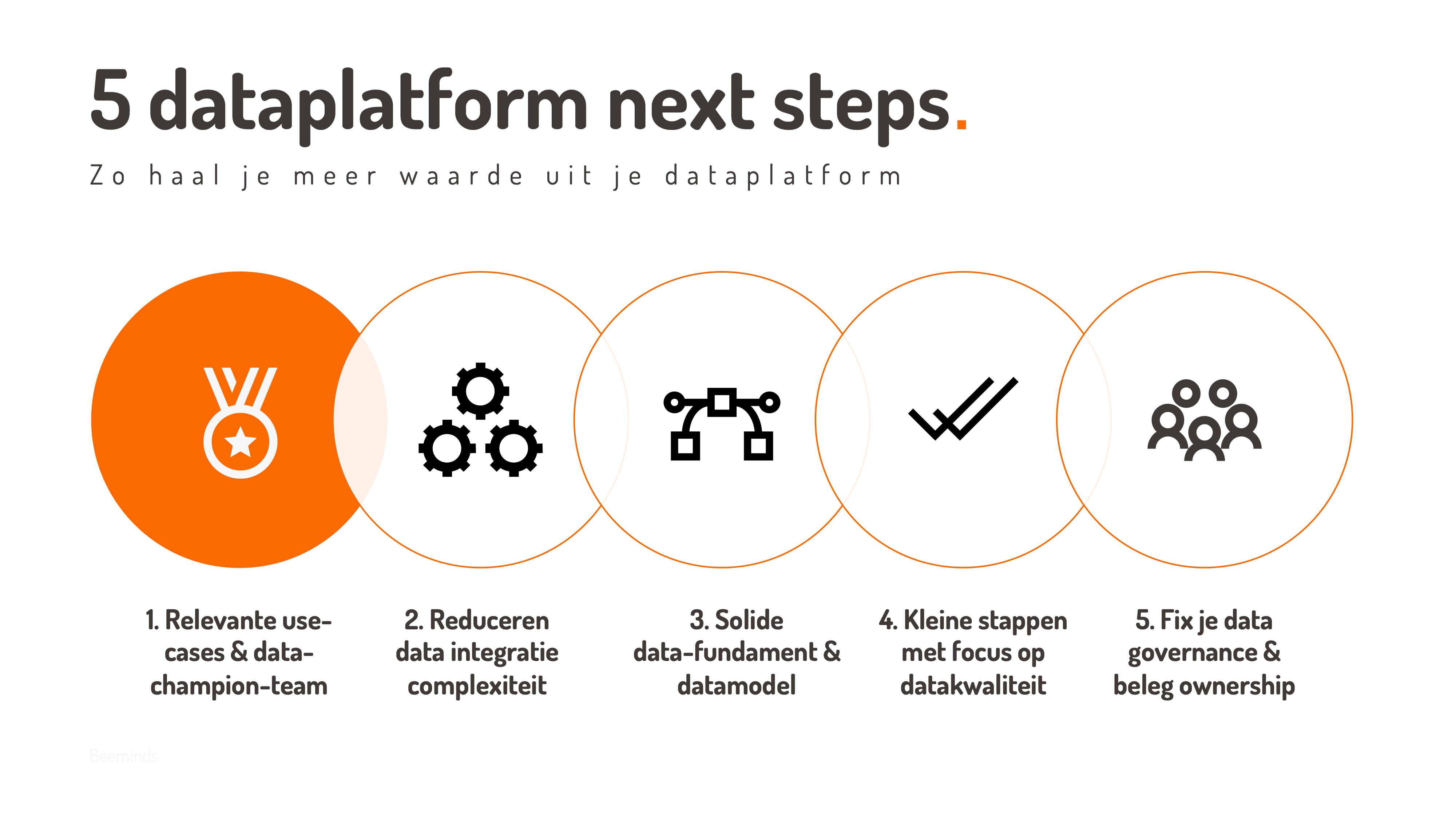
In deze blog geef ik 5 concrete vervolgstappen die je moet adresseren als onderdeel van de implementatie van je nieuwe dataplatform. Als je tenminste wil dat de data in je platform ook daadwerkelijk gebruikt wordt.
Behandel je nieuwe dataplatform als een elektrische auto

Voordat ik inga op de eerste post-dataplatform must-do, wil ik eerst even stilstaan bij al die nieuwe dataplatformen. Een goed dataplatform is namelijk belangrijk. Het is de motor van al je data-initiatieven. Sterker nog, het is meer dan een motor: het is je nieuwe auto waar je iedereen binnen je organisatie zich de komende jaren in gaat verplaatsen! Een elektrische auto om precies te zijn, als je het vergelijkt met de traditionele dataplatformen die vaak nog op niet cloud-native technologieën & platformen gebaseerd zijn.
De traditionele datawarehouses zijn vaak log & duur en kunnen niet 1:1 gemigreerd worden naar de cloud. Logisch dat je dan in 1x een modern dataplatform implementeert, toch? Ja, zeker. Maar net als bij het rijden van een elektrische auto vereist het op sommige onderdelen wel wat aanpassing. In theorie is een nieuw dataplatform (veel) goedkoper, efficiënter en sneller. Maar afhankelijk van hoe je het platform gebruikt kan dat nog best wel eens tegenvallen.
Hoe je zo’n modern platform optimaal inzet, is een ander onderwerp waar ik een aparte blog over zal maken in de toekomst. Wel wil ik één tip delen voor alle organisaties die aan de vooravond staan van de implementatie van een nieuw dataplatform:
Besteed niet meer dan twee maanden aan het volledig implementeren van een nieuw dataplatform!
Het volgen van deze tip heeft alleen ook één implicatie. En dat is dat je het dataplatform dus niet zelf gaat ontwerpen & implementeren! En dat is precies mijn punt: voor 95% van de organisaties heeft het geen enkele significante toegevoegde waarde om zelf een (nieuw) dataplatform te ontwerpen & implementeren. Doe dat dan ook niet, is mijn oproep!
Ga eens na: ga je echt meer onderscheidend worden als organisatie omdat je de solution architectuur van je dataplatform zelf bedacht hebt? Het antwoord is waarschijnlijk ‘nee’. Waar je je wel meer door kunt onderscheiden is door je tijd & energie te steken in het ontwikkelen van dataproducten met behulp van een platform dat je afneemt als een dienst. De verbeteringen die je hiermee kunt gerealiseerd op het gebied van efficiëntie, nieuwe omzet en klantbeleving zijn de zaken waar je je echt mee kunt onderscheiden! Ook als je daar nog niet aan toe bent en als eerste de stap naar de cloud wil maken met je datawarehouse, is een platform wat je af kunt nemen als een dienst een verstandige keuze.
Hoe dan ook zie ik dat er veel organisaties (te) snel grijpen naar zelfbouw, wat in veel gevallen niet nodig is. Mijn advies is dus:
Definieer eerst je ‘Buy vs. Build’ strategie. Ga na of je een eigen dataplatform moet ontwikkelen of dat je een geschikt platform kunt afnemen. Dit laatste is de logische keuze voor >95% van de organisaties.
Wanneer je dit besluit genomen hebt, kun je op zoek gaan naar een geschikt dataplatform dat je tegenwoordig als een dienst af kunt nemen. Daarbij is het belangrijk om antwoorden & uitgangspunten te formuleren op de volgende aspecten:
- Definieer welke soort datastromen het platform moet aankunnen
Data is er vele soorten & maten. Net hoe je bij een elektrische auto nadenkt over laadsnelheid, range & kofferbak ruimte, doe je dat ook bij een data platform.
- Definieer specifieke vereisten rondom security & data privacy
Een dataplatform bevat vaak veel gevoelige gegevens, dus het is belangrijk om helder te hebben of je hier te maken hebt met specifieke regels waar je rekening mee moet of wil houden.
Deze lijst is simpel en dat is bewust gedaan. Natuurlijk zijn er veel meer aspecten waar je op moet letten bij het selecteren van een platform, maar dat is niet heel veel anders dan bij het selecteren van elk ander platform of softwarepakket.
Doe je deze selectie goed, dan heb je binnen no-time een nieuw & ingericht modern data-platform, waarmee je daadwerkelijk aan de slag kunt en toegevoegde waarde gaat leveren aan je organisatie!
Must-do 1: vorm een data-team & focus op relevante use-cases
Tijd voor de eerste must-do! En dit is met reden nummer 1, want dit is direct iets waar het vaak misgaat. Zorg voor relevantie! Het klinkt heel logisch, maar aangezien veel organisaties data trajecten nog steeds vanuit een technisch perspectief aanvliegen, is het niet continue focussen op bedrijfsrelevantie een valkuil waar veel organisaties helaas nog steeds invallen.
Stel dus een multidisciplinair (virtueel) team samen met mensen die enthousiast zijn over de kansen van data en dit gezamenlijk concreet kunnen maken. Dit hoeft – zeker in het begin – geen fulltime rol te zijn, maar dat is natuurlijk afhankelijk van je datavolwassenheidsniveau & je ambitie. Laat het team werken aan een lijst (backlog) van relevante use-cases en maak die concreet met voorbeelden.
De volgende drie aspecten zijn belangrijk bij het vormen van dit team:
- Multidisciplinair:
selecteer & betrek mensen uit het operationele werkveld en vul dit aan met mensen die affiniteit hebben met data. IT kan zeker deelnemen, maar zorg dat IT niet dominant is. Het team vormen & beginnen vanuit enthousiasme is absoluut een goede aanpak en zorgt voor draagvlak binnen je organisatie. In een latere fase bijsturen (waar nodig) en het team aanpassen/uitbreiden kan altijd nog. - Sponsor
: Zorg voor een sponsor vanuit directie die actief deelneemt in de discussies & besluiten kan maken. Data maakt tegenwoordig vaak een (belangrijk) onderdeel uit van een strategie. Dit team zorgt ervoor dat je strategie tot executie kan komen. Een oproep aan de directies van organisaties om hier tijd voor vrij te maken. - Executiekracht
: zorg dat je minstens één iemand voldoende vrijmaakt om zaken uit te werken & concreet te maken. Doe dit het liefst met visuele voorbeelden zodat het communiceerbaar is. Dit kan je bijv. samen met een strategische leverancier oppakken of met je eigen data analisten en/of data-scientists.
Inspiratie als katalysator
Een van de belangrijkste taken van dit team is om je organisatie te inspireren zodat nieuwe ideeën loskomen en deze ideeën in lijn worden gebracht met je organisatiestrategie. Een goede manier om dit te doen is door interactieve workshops te organiseren.
Een veelgehoord bezwaar is dat de data-initiatieven uit de organisatie niet in lijn zijn met de strategie van de organisatie. In dat geval heb ik één tip: vraag aan de personen om je strategie op 1 sheet te presenteren. De kans is groot dat je strategie niet duidelijk (genoeg) is gecommuniceerd.
Nieuwe ideeën hoeven overigens niet altijd innovatief te zijn. We vergeten vaak dat innovatie een middel is & niet het doel en dat innovatie voor elke organisatie iets anders kan betekenen. Voor de ene sector is een nieuwe digitale assistent die aangedreven wordt door ChatGPT en je klantvragen afhandelt innovatief, terwijl de andere sector erg geholpen is met een ‘simpel’ dashboard waarmee ze de marge per klant kunnen zien.
Must-do 2: reducer data integratie complexiteit
Veel tijd & energie gaat verloren in iets dat wel belangrijk is, maar niet zoveel tijd & energie hoeft te kosten. Het gaat hier over het ontsluiten & inlezen van de data in je dataplatform, ook wel ‘data integratie’ genoemd.
Deze integraties – vaak ook wel aangeduid als ETL of ELT– worden ondergebracht in data-pipelines en zijn essentieel bij het beschikbaar stellen van data aan je organisatie. Als een data-pipeline niet goed werkt, is de kans dat de data die getoond wordt in je dashboards niet klopt of dat je voorspellende AI/Machine Learning model niet werkt. Data pipelines kun je tegenwoordig op een no-code manier
implementeren, maar veel data engineers geven de voorkeur aan code-driven pipelines, waardoor je afhankelijk bent van specialistische kennis bij een incident. Natuurlijk zijn er soms ook goede redenen om een data-pipeline ‘te programmeren’, maar met een goede data architectuur & tooling hoeft dat tegenwoordig niet meer ‘de standaard’ te zijn. Stel dus een ‘guideline’ op voor je data & IT teams wanneer ze voor welke oplossingsrichting moeten kiezen.
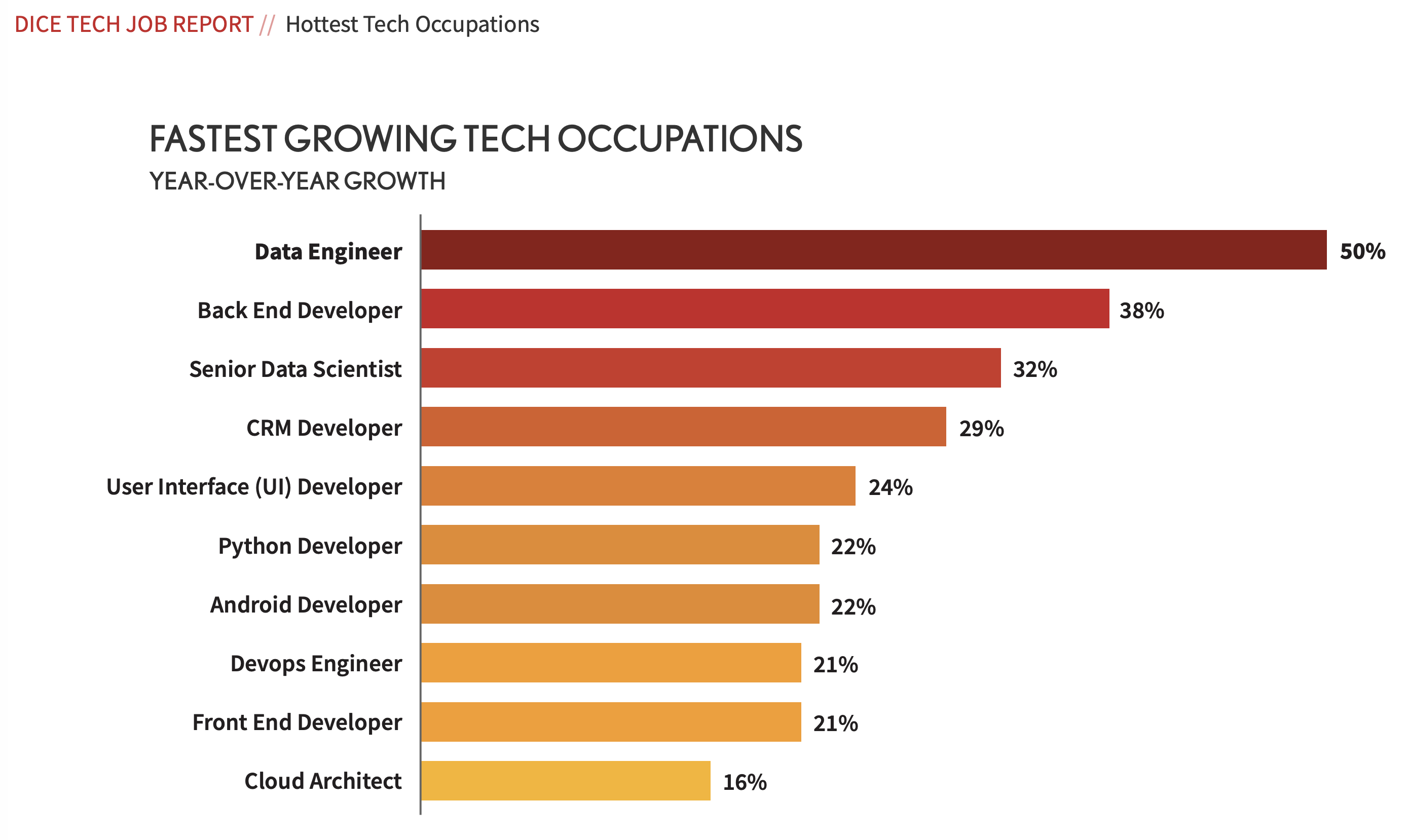 Data Engineer: een populair beroep
Data Engineer: een populair beroep
Indien je afhankelijk bent van data in je primaire proces is er zelfs iets voor te zeggen dat je dit 24×7 in de gaten wil houden. Het is daarom ook logisch dat ‘data engineer’ een van de meest populaire beroepen van deze tijd is:
Data Integratie as-a-Service
Kies dus, als het kan & logisch is, voor een integratie oplossing die je ‘As-a-Service’ kunt afnemen. Er zijn tegenwoordig tal van connectoren of integraties te vinden die je af kunt nemen als een dienst (data-integratie-as-a-service) voor een vast bedrag per maand. Een van de grote voordelen hiervan is dat je het beheer & onderhoud van de koppeling uitbesteedt aan een partij die een team heeft die dit 24×7 kan monitoren en er op aangesproken wordt zodra er iets niet (goed) werkt.
Want zeg nu zelf… Het enige waar het om gaat is dat de data op een veilige & betrouwbare manier in je dataplatform terecht komt. De tijd die het je oplevert omdat je dit niet zelf hoeft op te zetten en te onderhouden kun je besteden aan eventuele speciale applicaties waarvoor géén as-a-service integratie beschikbaar is of ervoor zorgen dat je je meer focust op het verhogen van de datakwaliteit. Dit laatste gaat je gegarandeerd meer voordelen opleveren bij het succesvol inzetten van data binnen je organisatie.
Must-do 3: Creëer een data fundament & begin met een gedragen datamodel
Het hiervoor besproken koppelen van systemen wordt vaak als het startpunt gezien van de data-reis. Ergens logisch, aangezien je data nodig hebt om aan de slag te kunnen met data.
Toch is dit vreemd, want zelfs in de meest agile & innovatieve omgevingen is het principe “first think, then do” nog steeds van toepassing. Mijn oproep aan organisaties – om het werken met data beheersbaar & betaalbaar te houden – is dus ook:
Begin met je data end-state, en vul je data model op een gefaseerde & gestructureerde wijze. First design, then build!

Onderdeel van die end-state is niet alleen je datamodel, maar ook welke dataproducten voor jouw organisatie relevant zijn en hoe die dan uit moeten zien. Ik kwam laatste deze (oude) quote tegen in relatie tot de AI revolutie die nu gaande is, maar ook hier is die van toepassing.
Beginnen met het doel én design de ‘end-state’
Maak een overzicht welke data je echt nodig hebt om een bepaalde use-case op te leveren en laat deze landen in een goed doordacht datamodel. Op deze manier is de data duidelijk gedocumenteerd & vindbaar en kun je datakwaliteitsregels opstellen om ervoor te zorgen de data van gegarandeerde hoge kwaliteit is.
Deze aanpak kent 3 belangrijke voordelen:
- Geen ‘over-engineering':
voorkomen van onnodige complexiteit & onderhoud omdat je applicaties of gegevens die je niet nodig hebt niet ontsluit en dus ook niet hoeft te onderhouden. Data pipelines kunnen naarmate de tijd verstrijkt behoorlijk complex worden omdat ze veel bewegende onderdelen bevatten, dus hoe minder ongebruikte functionaliteiten ze bevatten; hoe beter. Je voorkomt hiermee ‘over-engineering’ - Snelheid & eenvoud:
je maakt het werk voor je data engineers makkelijker omdat je een goed doordachte landingsplek (datamodel) aanbiedt waar de data ‘in moet passen’. Dit verhoogt tevens de kwaliteit. - Effectiever & efficiënter:
je bepaalt de behoefte van een bepaald data product (use case) voordat je vaak schaarse technische resources besteed aan het bouwen van een nieuwe integratie. Het helpt je dus in het creëren van relevante dataproducten die – wanneer je data governance proces goed zijn werk doet – in lijn zijn met je data strategie. Mijn collega Gerbrand Tjaden heeft recent een blog geschreven over hoe je een effectief datawarehouse neerzet dat daadwerkelijk aansluit bij de behoefte van een organisatie. In deze blog komt dit punt ook nadrukkelijk naar voren en hiermee sla je dus in feite 2 vliegen in 1 klap. Laaghangend fruit dus!
In de laatste 5 jaar is data modellering een ‘lost art’ geworden, aangezien de laatste jaren veel werd ingezet op datalakes waarbij je data in ruw formaat wegschrijft zonder dat het datamodel bekend hoeft te zijn. Dit heeft echter geresulteerd in veel data swamps i.p.v. data lakes, waardoor o.a. data modelering weer populariteit aan het winnen is.
Dat het belang van het hebben van een goed data fundament weer terugkomt, is wat ons betreft helemaal terecht. Een goed doordacht datamodel kent vele voordelen, waarvan ik er hier 3 noem:
- Gedocumenteerd & doorzoekbaar:
als je weet welke gegevens je wil opnemen in je model, kun je deze velden ook documenteren. Je hoeft het immers maar op 1 plek bij te houden. Als bijkomend voordeel kun je deze gegevens ook doorzoekbaar maken voor eindgebruikers met een data catalogus en deze documentatie tonen in je data analyse tool, waardoor bijvoorbeeld precies duidelijk is hoe je YoY marge ontwikkeling berekend wordt. - Gevalideerd & herkenbaar:
een goed datamodel is herkenbaar & begrijpbaar voor de (eind)gebruikers. Je kunt dit valideren en daarmee het draagvlak verhogen. Het wordt dus eenvoudiger om te beginnen met het realiseren van dataproducten op basis van een goed doordacht datamodel. - Hogere adoptie & transparantie:
gevalideerde data die doorzoekbaar is, zal zorgen voor een hogere adoptie van data binnen je organisatie, aangezien het eenvoudiger is om van start te gaan. Daarnaast helpt het ook bij het beleggen van ownership van data. Dit laatste is vooral van belang bij decentrale data governance frameworks zoals data-mesh waar je werkt met data contracten. Hier staat data-ownership centraal. Ook helpt het dat wanneer gebruikers vragen hebben over bepaalde gegevens, dat ze weten bij wie ze terecht kunnen.
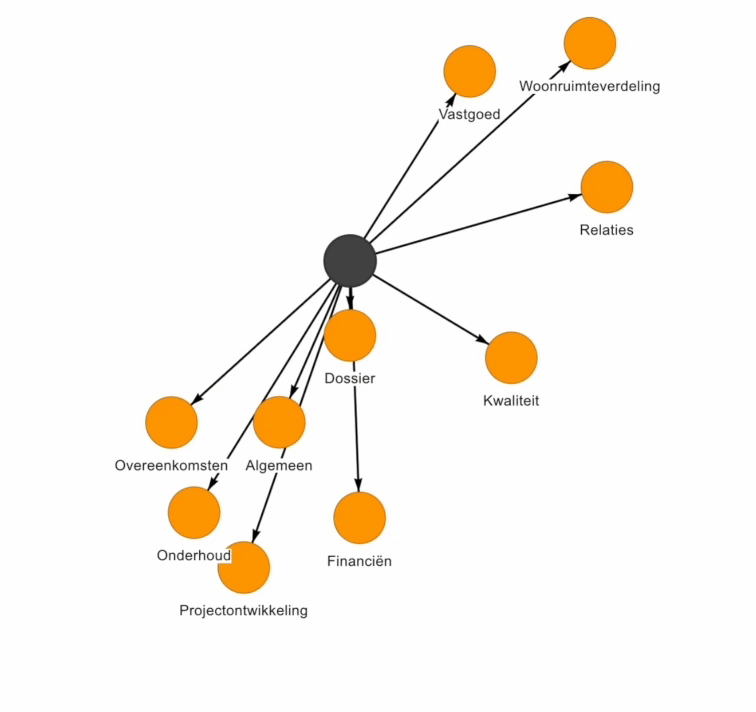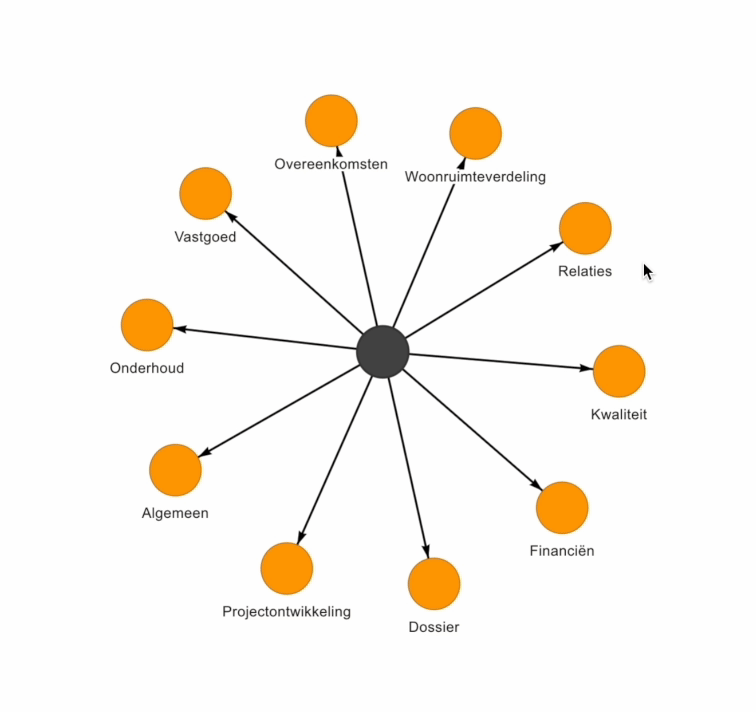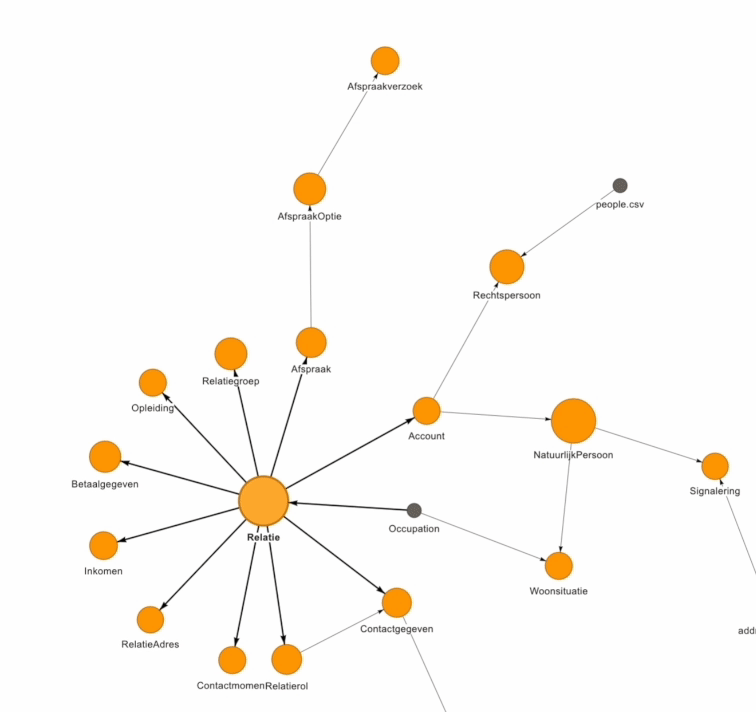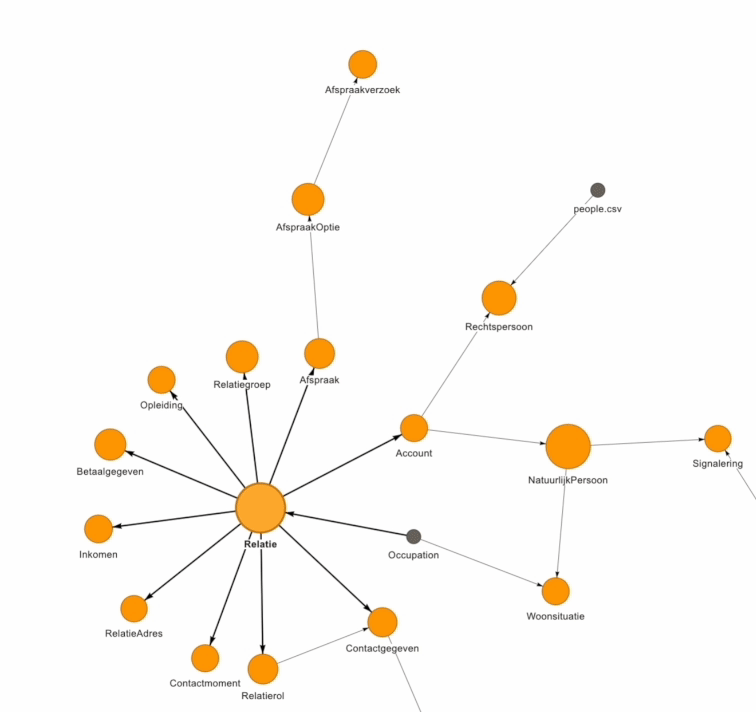
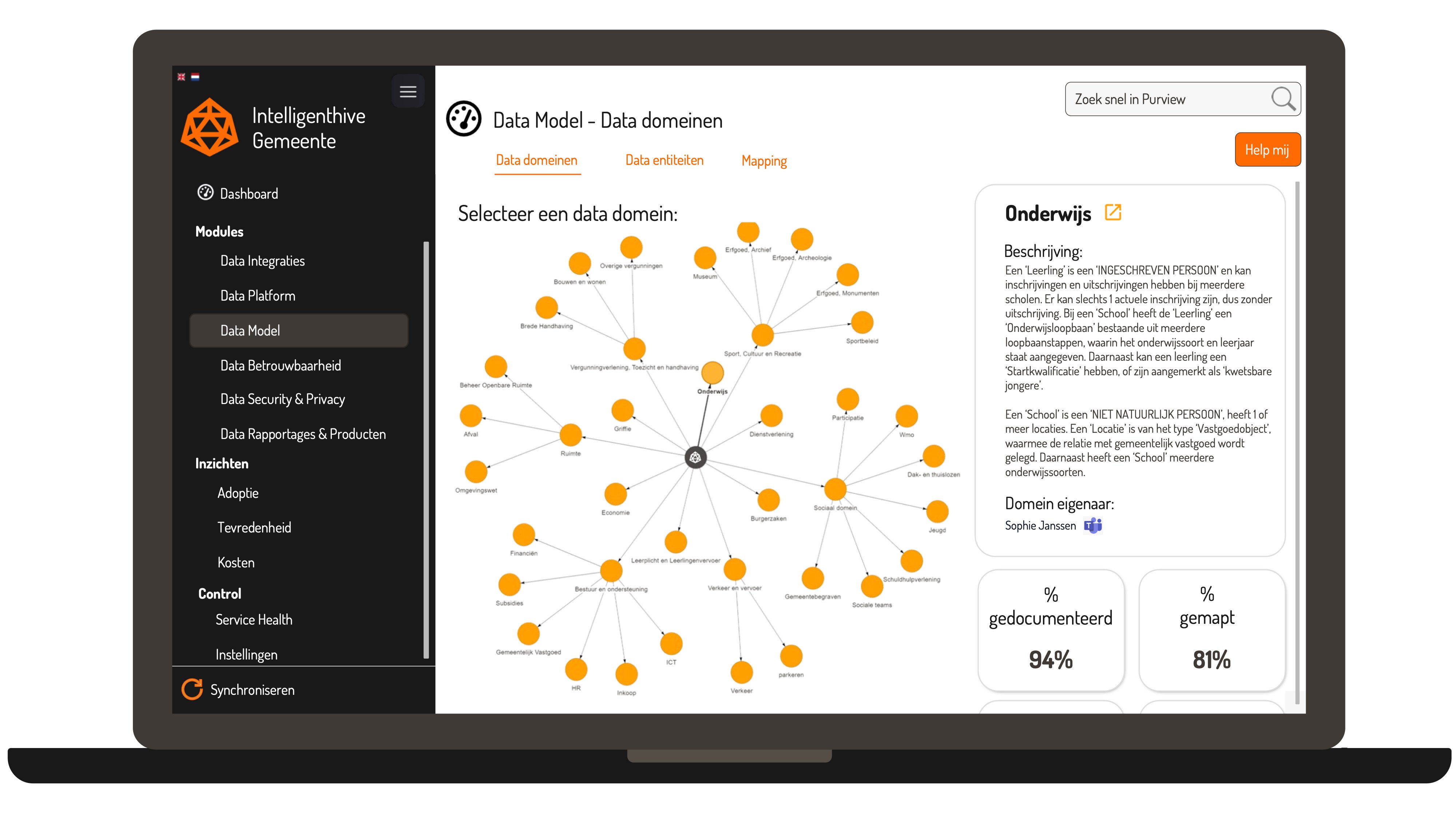
Een datamodel of Enterprise Data Model (EDM) kan behoorlijk complex zijn om te visualiseren. Bij Beeminds maken we gebruik van een visuele weergave om de data domeinen & data entiteiten en de relaties daartussen op een simpele & interactieve wijze inzichtelijk te maken voor de organisatie:
Must-do 4: Zet kleine stappen met focus op datakwaliteit
De meest gehoorde uiting bij het inzetten van dataproducten binnen organisaties is de opmerking: “ik weet niet of ik de data kan vertrouwen…”
Vaak wordt dit gebrek aan vertrouwen gevoed door complexe dashboards die meer vragen oproepen dan beantwoorden en door conclusies & inzichten die simpelweg niet uitlegbaar zijn. Een cruciaal moment voor het bouwen of verliezen van dit vertrouwen is de lancering & presentatie van een KPI of inzicht op basis van de data. Op basis van de herkenbaarheid & uitlegbaarheid van de getoonde gegevens wordt er onmiddellijk een conclusie getrokken door de mensen die hier belang bij hebben. Worden de getoonde gegevens niet herkend of begrepen, dan zal dit onherroepelijk een negatieve impact hebben op het vertrouwen in de oplossing. Volg de volgende 3 stappen:
- Begin klein:
natuurlijk willen we graag 1 dashboard waar alle gewenste inzichten in gegeven worden, maar helaas is dat niet mogelijk. Sterker nog: dit verhoogt alleen maar het risico dat je dashboard niet begrepen & gebruikt worden. Begin dus klein en met maximale relevantie om dit risico te mitigeren. - Valideer:
zorg dat je inzichten valideert met de meest belangrijke stakeholders en stel ze de volgende 2 vragen: “herken je de getoonde inzichten?” en “kloppen de getoonde inzichten?”. Het kan namelijk best zo zijn dat jouw inzichten correct zijn met conclusies die nog niet eerder bekend waren. Als dat zo is dan beïnvloedt vraag 1 het antwoord op vraag 2. Er is een verschil tussen ‘gelijk hebben’ en ‘gelijk krijgen’. Valideer dus je dataproducten zodat eventuele onduidelijkheden vóór de lancering zijn weggenomen. - Leg uit:
zorg dat je je inzichten logisch opbouwt & uitlegt. Leg zichtbaar aan de gebruikers uit hoe bepaalde berekeningen of grafieken zijn opgebouwd en zorg voor duidelijke omschrijvingen van de gegevens. Heb je bepaalde gegevens uitgesloten? Vermeld dit dan ook.
Datakwaliteit
Toch ben je er niet met bovenstaande stappen. Want als je eenmaal je dataproduct gelanceerd hebt, is het van groot belang dat je in de gaten houdt of de getoonde data nog steeds correct is. Datakwaliteit is een belangrijk proces dat je dus niet alleen tijdens, maar ook na de realisatie moet borgen. De gebruikte data is namelijk een ‘bewegend doel’ dat continue veranderd. Om grip hierop te krijgen zijn de volgende zaken essentieel:
- Maak afspraken met applicatie eigenaars
Zorg dat je transparant bent richting de eigenaren van de applicaties waar je data uit komt en maak inzichtelijk welke data & op welke wijze je deze gebruikt. Door het communiceren van je afhankelijkheid creëer je bewustzijn en verlaag je het risico op data veranderingen waardoor je verrast wordt.
- Beleg data ownership
Zorg dat je een duidelijke eigenaar hebt aangewezen die je data bewaakt. Lees hierover meer in de laatste ‘must-do’ nummer 5.
- Stel (automatische) datakwaliteitsregels op
Door het opstellen van een aantal datakwaliteitsregels die automatisch gecontroleerd worden, voorkom je al veel fouten. Deze regels hebben één doel, namelijk het versturen van een signaal naar de juiste persoon die daar iets mee kan doen. Datakwaliteitsregels kunnen relatief eenvoudig worden opgesteld op basis van een huidige dataset, zeker wanneer je gebruik maakt van standaard frameworks. Bij Beeminds gebruiken wij het Great Expectations framework, dat naadloos integreert in vrijwel elk dataplatform.Daarnaast is het heel nuttig om datakwaliteit te monitoren op basis van het verleden (trends). We weten allemaal dat behaalde resultaten in het verleden natuurlijk geen garantie voor de toekomst zijn, maar als je elke dag 1.200 gewijzigde records inleest en opeens zijn er dit er structureel nog maar enkele, dan is dat minimaal een reden om een signaal af te geven. Een dashboard om zulke controles & signalen mee uit te voeren leveren wij standaard mee bij elke use-case en levert een significante meerwaarde op in elk datatraject.
Must-not-do
Wat minstens zo belangrijk is, is wat je niet moet doen. En dat is wat mij betreft het ‘oplossen’ van slechte datakwaliteit in de (business) logica je dataplatform. Je creëert hiermee logica die complex is om te onderhouden, aangezien je het probleem niet structureel oplost. Dweilen met de kraan open dus. Ga altijd in gesprek met de eigenaar van een applicatie om te kijken of je het probleem bij de bron kunt oplossen.
Must do 5: Beleg ownership & fix je data governance
Zoals eerder aangegeven focussen veel dataplatform implementaties zich op technologie. Data governance & data ownership kun je ondersteunen met technologie, maar gaat in de basis over afspraken, processen & je organisatie.
In de eerdere must-do’s is data ownership al meerdere keren voorbijgekomen en het is belangrijk dat je hier goed over nadenkt. Met data ownership bedoel ik niet het beleggen van alle data gerelateerde zaken bij één persoon die er het meeste vanaf weet. In het begin lijkt dit de meest voor de hand liggende oplossing, maar al snel leidt dit tot twee grote nadelen:
- Bottleneck & snelheid
Wanneer de adoptie van data toeneemt (en dat gaat het doen, want je hebt de eerste 4 punten opgevolgd ;-)), zul je al snel zien dat het bij 1 persoon beleggen van alle data gerelateerde uitdagingen gaat zorgen voor een bottleneck waardoor de snelheid van het opleveren van dataproducten en het oplossen van problemen achteruit gaat.
- Geen uitdaging & verloop
Data ownership gaat vaak gepaard met operationeel werk. Het beleggen van alle operationele datawerkzaamheden bij één getalenteerde persoon zal leiden tot minder uitdagend werk. Wanneer je getalenteerde mensen volstopt met operationeel werk en niet uitdaagt, loop je het risico dat deze mensen in een bore-out terecht komen en zelfs uiteindelijk je organisatie verlaten.
Maak data ownership transparant en communiceer dit met de organisatie. Met een data catalogus zoals Microsoft Purview wordt dit heel eenvoudig:

Kortom: houd je data organisatie agile en spreid vanaf het begin je data ownership binnen je organisatie. Het helpt daarnaast ook bij het creëren van een breder draagvlak & het verhogen van de adoptie.
To data mesh or not to data mesh?
Tegenwoordig overwegen veel organisaties ‘Data Mesh‘ als benadering om data governance goed te organiseren binnen je organisatie. Ook biedt het recent aangekondigde Microsoft Fabric & OneLake native ondersteuning voor Data Mesh. Welke manier van organiseren het beste bij je past schrijf ik binnenkort een blog over.
Het doel? Meer relevante data & minder complexiteit
Ik hoop dat ik met deze 5 concrete must-do’s & tips jullie een zetje in de juiste richting heb gegeven wanneer je overweegt een nieuw dataplatform te gaan implementeren of wanneer je dit al gedaan hebt.
Mijn doel hiermee is simpel: meer focus op relevantie, maar met minder complexiteit. Laten jullie mij weten of je iets aan deze blog hebt gehad?
Data-as-a-Service reduceert complexiteit
Bij Beeminds maken we zaken graag simpel en geloven we erin dat de weg naar datagedreven werken voor organisaties korter kan. Data als water uit de kraan, dat is onze belofte!
En dat is precies wat we waarmaken met onze Intelligenthive oplossing. Bovenstaande onderwerpen zijn uiteraard daarin meegenomen en neem je bij ons af als een dienst met een servicelevel dat bij jouw organisatie past.
Benieuwd hoe wij deze uitdagingen oplossen en jouw organisatie voorzien van een data fundament? Plan dan vandaag nog een demo in en laat je overtuigen!
Bericht delen:































