Sinds de doorbraak van ChatGPT, Claude en Gemini is kunstmatige intelligentie niet meer weg te denken op de werkplek. Medewerkers gebruiken AI om teksten te schrijven, documenten samen te vatten, code te genereren of sneller informatie op te zoeken. Deze toepassingen vallen onder wat we generatieve AI noemen: technologie die nieuwe content creëert op basis van bestaande kennis en patronen.
Toch zien we dat organisaties nu een volgende stap zetten en niet alleen antwoorden willen op basis van algemene kennis, maar ook op basis van hun eigen bedrijfsdata. Een salesmanager wil weten waarom de omzet achterblijft. Een financieel directeur wil inzicht in marges. Een operationeel manager wil begrijpen waar vertragingen in processen ontstaan. Op dat moment ontstaat de behoefte aan een ander type AI: de data agent.
Voor veel organisaties klinkt dat als de volgende stap in datagedreven werken. Maar wie verder kijkt dan de AI hype, ontdekt dat niet iedere data agent dezelfde kwaliteit levert. Sommige agents geven verrassend goede antwoorden. Andere produceren inzichten die logisch klinken, maar inhoudelijk niet kloppen. Dat roept een belangrijke vraag op: Wat maakt een data agent eigenlijk slim?
Waarom veel data agents ervaringen tegenvallen
Neem een eenvoudige vraag als: "Hoeveel actieve klanten hebben we?"
Voor een mens lijkt dat een duidelijke vraag. Voor een data agent niet. Wat verstaan we onder een actieve klant? Een klant met een order in de afgelopen maand? In de afgelopen twaalf maanden? Of alleen klanten binnen een specifieke business unit?
Stel je voor dat morgen een nieuwe medewerker begint binnen jouw organisatie. Op zijn eerste werkdag krijgt hij toegang tot alle systemen. Hij kan het CRM openen, financiële cijfers bekijken en rapportages analyseren. Technisch gezien heeft hij toegang tot dezelfde informatie als een ervaren manager.
Toch zou niemand verwachten dat hij direct strategische beslissingen kan nemen. Hij kent de organisatie niet. Hij begrijpt de processen nog niet. Hij weet niet welke definities worden gehanteerd of welke uitzonderingen er bestaan.
De data is beschikbaar. De context ontbreekt. En precies dat zien we ook terug bij data agents.
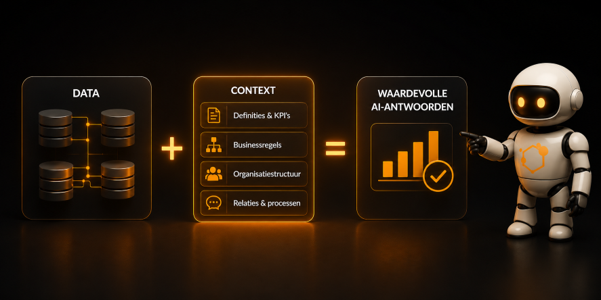
Waarom context cruciaal is voor AI adoptie
Traditionele dashboards zijn ontworpen voor mensen. Een gebruiker ziet een KPI en begrijpt vaak intuïtief wat deze betekent. Hij kent de organisatie, spreekt dezelfde taal als zijn collega’s en weet welke definities worden gehanteerd.
Een data agent beschikt niet over die achtergrondkennis. Voor AI bestaat een KPI uitsluitend uit data en metadata. Als definities ontbreken of businessregels nergens zijn vastgelegd, moet de agent zelf gaan interpreteren.
Dat leidt tot een bekend patroon. De antwoorden klinken overtuigend, maar blijken bij controle niet volledig juist te zijn. Niet omdat de technologie tekortschiet, maar omdat de context ontbreekt die nodig is om de data correct te begrijpen.
Juist daarom verschuift de aandacht steeds meer van AI naar de kwaliteit van het onderliggende datalandschap.
Waar data agents echt waarde toevoegen
Wanneer data en context samenkomen, ontstaat de echte kracht van data agents.
Wij zien vooral veel potentie in situaties waarin gebruikers niet op zoek zijn naar een standaardrapport, maar naar een antwoord op een specifieke vraag.
Denk bijvoorbeeld aan een manager die ziet dat de omzet is gedaald en direct wil begrijpen waar dat door komt. In plaats van meerdere rapportages te openen en zelf analyses uit te voeren, kan een data agent verschillende perspectieven onderzoeken en mogelijke verklaringen aandragen.
Ook bij meer verkennende analyses zien we veel toegevoegde waarde. Gebruikers kunnen vragen stellen die vooraf niet zijn bedacht en op een natuurlijke manier door de data navigeren. Dat maakt data toegankelijk voor een veel grotere groep medewerkers.
"Data agents werken steeds vaker samen met andere agents vanuit je werkplek. Een analyse-agent ontdekt een kans, een CRM-agent zoekt de juiste klanten erbij en een andere agent bereidt direct een vervolgactie voor. Daarmee verschuift AI van een losse tool naar een actieve deelnemer in bedrijfsprocessen."

Een stevig datafundament met de Intelligenthive®
Wanneer definities ontbreken, databronnen elkaar tegenspreken of niemand precies weet hoe KPI’s worden berekend, zal AI die problemen niet oplossen. Sterker nog, ze worden vaak sneller zichtbaar doordat gebruikers rechtstreeks vragen stellen aan de data en onbetrouwbare antwoorden genereren.
Daarom begint succesvolle AI niet bij AI, maar bij een stevig datafundament waarin data, definities en businesskennis op een consistente manier zijn vastgelegd. Bij Beeminds zien we dat veel organisaties al beschikken over waardevolle data. Wat vaak ontbreekt, is de context die nodig is om die data betrouwbaar inzetbaar te maken voor AI.
Met de Intelligenthive® brengen we data, businessregels, definities en relaties samen in één centrale omgeving. Zo ontstaat een fundament dat niet alleen begrijpelijk is voor mensen, maar ook voor AI.
Daardoor verandert een data agent van een slimme stagiair met toegang tot alle systemen in een ervaren collega die begrijpt hoe de organisatie werkt. Niet omdat de technologie slimmer wordt, maar omdat de context beschikbaar is die nodig is om de juiste conclusies te trekken.
Zelf aan de slag met data agents
Wil je zelf aan de slag met data agents? Dat kan. In één dag ervaar je hoe AI naar data kijkt en leer je hoe je komt tot data agents die je daadwerkelijk betrouwbare antwoorden te geven.
Ontdek onze hands-on trainingen en meld je direct aan!

Bericht delen:
































